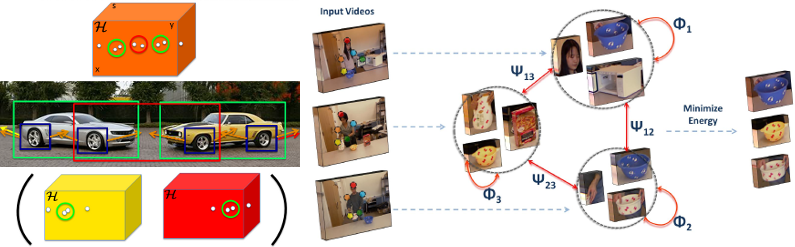
Left: During detection, Hough forests cast weighted votes to a Hough space (orange) where objects are detected by localizing modes. Improved performance can be realized by using latent Hough spaces thereby relaxing the patch independece criterion. Right: Instances of common objects in videos are discovered by defining a model that encodes similarity of their appearance and functionality.
Object detection for real world applications is still a challenging problem. While increased data can partly solve the problem, the ability of detectors to process large data sets in reasonable time becomes another important issue besides accuracy.
A family of methods that can handle large amount of training data efficiently, and that are inherently suited for multi-class problems, are based on random forests, which are ensembles of randomized decision trees that can be applied to regression or classification tasks. Since object detection involves both classifying patches belonging to an object and using them to regress the location and scale of the object, random forests for object detection need to be trained to satisfy both objectives [ ].
While object detection based on Hough forests allows parts observed in different training instances to support a single object hypothesis, it also produces false positives by accumulating votes that are consistent in location but inconsistent in other properties like pose, color, shape or type. To address this problem, Hough forests can be augmented with latent variables in order to enforce consistency among votes [ ]. To this end, only votes that agree on the assignment of the latent variable are allowed to support a single hypothesis.
In order to avoid an expensive manual labeling process, or to learn object classes autonomously without human intervention, we propose a framework for object discovery in activity-labeled videos [ ]. Since small objects like pens are difficult to discover only based on appearance, we introduce similarity based on object functionality, which can be estimated from relative human-object motion during the activity. We show that functionality is an important cue for discovering objects from activities in RGB(D) video datasets.