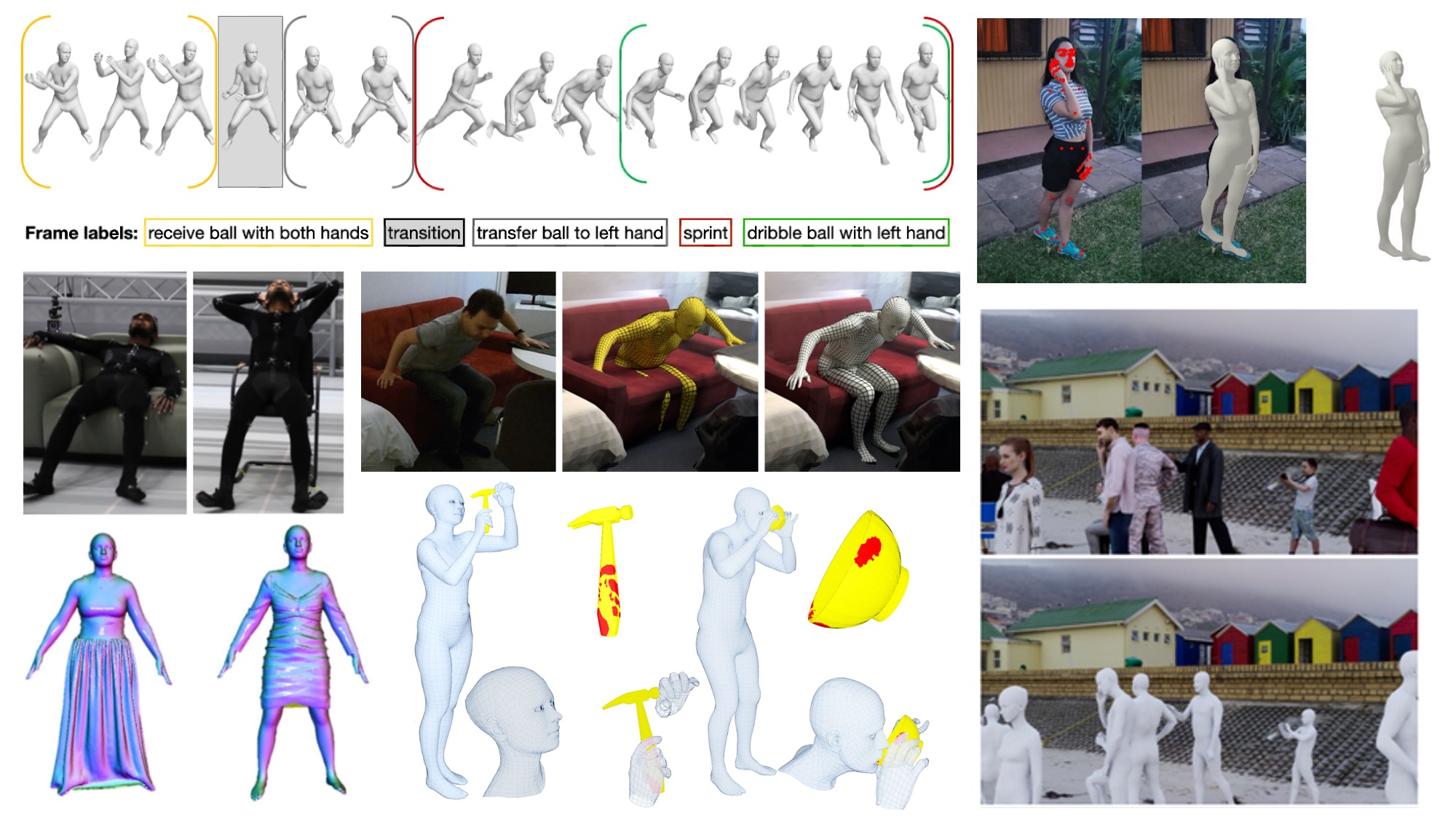
A few example datasets: BABEL, Mimic-the-Pose (MTP), AGORA, GRAB, ReSynth, SAMP, and PROX.
Datasets with ground truth have driven many of the recent advances in computer vision. They allow evaluation and comparison so the field knows what works and what does not. They also provide training data to machine learning methods that are hungry for data. Code is equally important as it supports reproducible research and enables the field to build on past results. With freely available data and code, the whole field moves faster.
We have played central roles in many influential datasets and evaluations in the field including Middlebury Flow, Sintel, KITTI, HumanEva, FAUST, JHMDB, and others. Over the last six years we have released several major datasets related to faces, hands, 3D bodies, clothing, animals, and optical flow.
A full list of our code and data can be accessed here: https://ps.is.tuebingen.mpg.de/code
Popular recent datasets include
- FLAME [ ]: FACE model, fitting code, and registered meshes
- CoMA [ ]: 20,466 3D face meshes of extreme expressions with 12 subjects
- MANO [ ]: hand scans and parametric 3D hand model
- Dynamic FAUST [ ]: precise 4D scans in correspondence
- 3DPW [ ]: 3D poses in the wild for training and evaluation of human pose and shape estimation
- SURREAL [ ]: synthetic humans for training deep networks
- SlowFlow [ ]: optical flow in real scenes
- Unite the People [ ]: training set for 3D human pose from images
- BUFF [ ]: body shape under clothing
- VOCA [ ]: 4D face dataset with about 29 minutes of 3D scans and registered meshes, with audio, from 12 speakers
- DIP [ ]: code and data for 3D human pose from IMUs
- NoW challenge [ ]: images of faces with 3D ground truth and an evaluation system
- Human Optical Flow [ ]: code and data for optical flow of humans from an RGB image
- LTSH [ ]: data and code for multi-person 2D human pose estimation from an RGB image
- ObMan [ ]: data and code for 3D hand-object reconstruction from an RGB image
- CAPE [ ]: 3D meshes of dressed humans for training models of clothed humans
- PROX [ ]: data and code for 3D humans interacting with rigid 3D scenes from an RGB/RGB-D image
- ExPose [ ]: data and code for predicting expressive 3D humans from an RGB image
- GRAB [ ]: data for 3D human-object whole-body grasps, data and code for generating 3D hand grasps for unseen 3D objects
- AMASS [ ]: large dataset of mocap datasets in a unified SMPL-based representation
- SAMP [ ]: MoShed mocap data including interaction with 3D objects
- ReSynth [ ]: animated 3D bodies draped in clothing using physics simulation
- TUCH [ ]: ground truth 3D humans with self contact
- SPEC [ ]: multiple datasets for dealing with human pose estimation with perspective cameras
- BABEL [ ]: AMASS motions with fine-grained action labels
- AGORA [ ]: ground truth SMPL-X bodies for photo-realistic images with multiple people














