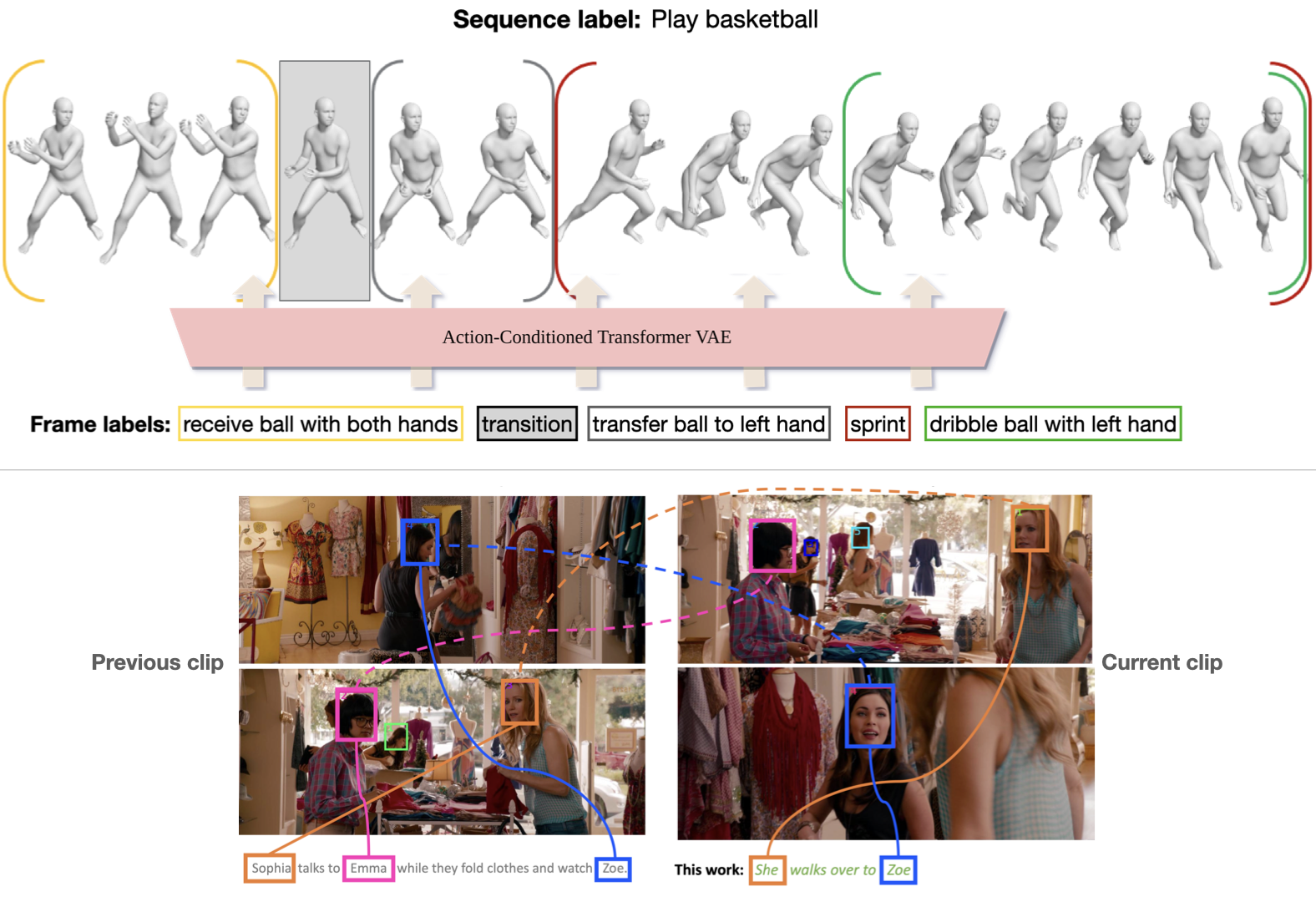
Top: Our goal is to generate 3D human movements that are grounded in actions using the BABEL dataset [ ], which consists of dense frame-level action labels that correspond to 3D human movements. Bottom: We identify individual actors in a movie clip and synthesize natural language descriptions of their actions and interactions [ ].
Understanding human behavior requires more than 3D pose. It requires capturing the semantics of human movement — what a person is doing, how they’re doing it, and why. The what and why of human movement — the actions of a person, their goals, emotions, and mental states — are typically described via natural language. Thus, grounding human movement in language, is a key to modeling and synthesizing human behavior.
Progress in this requires 3D movement data that is precisely aligned with action descriptions. In BABEL [ ] we label (>250) actions performed in (>43 hours) mocap sequences from AMASS [ ]. Fine-grained "frame labels" precisely capture the duration of each action in a sequence. BABEL is being leveraged for tasks like action recognition, temporal action localization, and motion synthesis.
Since 3D mocap data will always be limited, we would like to learn language-grounded movement from video. Our approach identifies individual actors in a movie clip and synthesizes language descriptions of their actions and interactions [ ]. The approach first localizes characters by relating their visual appearance to mentions in the movie scripts via a semi-supervised approach. This (noisy) supervision greatly improves the performance of a description model.
ACTOR [ ] is an example of our work on synthesizing human movement, conditioned on action labels. Despite being trained with noisy data estimated from monocular video, ACTOR's transformer VAE architecture learns to synthesize diverse and realistic movements of varied length.