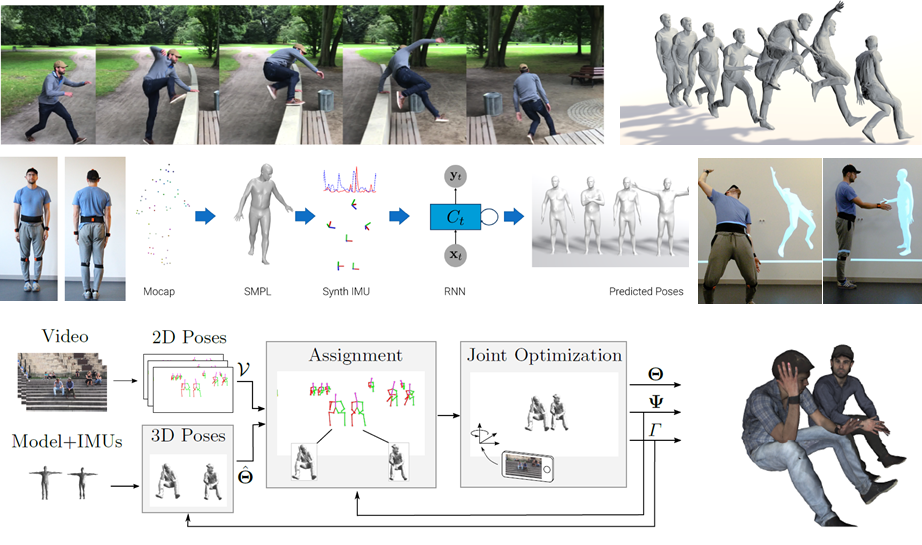
Overview. Top row: Unconstrained human motion capture using SIP. Mid row: In DIP, we synthesize an IMU dataset, and leverage that to train an RNN regressor, improving SIP both in accuracy and runtime. Bottom row: Using VIP, we combine videos with sparse IMUs to collect 3DPW, a new dataset of accurate 3D human poses in natural scenes, containing variations in person identity, activity and clothing.
Marker-based optical motion capture (mocap) systems are intrusive and restrict motions to controlled laboratory spaces. Therefore, simple daily activities like biking, or having coffee with friends cannot be recorded with such systems. To address this, and record human motion in everyday natural situations, we develop novel systems based on Inertial Measurement Units (IMUs), that can track the human pose without cameras, making them more suitable for outdoor recordings.
Existing commercial IMU systems require a considerable number of sensors, worn on the body or attached to a suit. These are cumbersome and expensive. To make full-body IMU capture more practical, we developed Sparse Inertial Poser (SIP) [ ], which recovers the full 3D human pose from orientation and acceleration measrued by only 6 IMUs attached to the wrists, lower legs, waist and head. This setup is a minimally intrusive solution to capture human activities.
SIP gives an offline, non-intrusive, mocap system that can be used in unconstrained settings of daily life, but the method does not run in real time. In Deep Inertial Poser (DIP) [ ], we go beyond the accuracy of SIP and further make it real time. To this end, we synthesize a large IMU dataset from motion capture data and leverage that to learn a deep recurrent regressor that produces SMPL pose parameters in real time from 6 IMU sensor recordings.
While portable, IMU systems are prone to drift. To address this we combine IMUs with a moving camera and current 2D pose-detection methods. Our VIP system [ ] solves for the body movements that match the IMU data and project into the image to match 2D joints. Using VIP, we collected the 3DPW dataset, that includes videos of humans in challenging scenes with accurate 3D parameters that will provide the means to quantitatively evaluate monocular methods in difficult scenes.