2024
PuzzleAvatar: Assembling 3D Avatars from Personal Albums
Xiu, Y., Liu, Z., Tzionas, D., Black, M. J.
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published

StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y., Dong, Z., Bo, L., Xiu, Y., Han, X.
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published
Re-Thinking Inverse Graphics with Large Language Models
Kulits, P., Feng, H., Liu, W., Abrevaya, V., Black, M. J.
Transactions on Machine Learning Research, August 2024 (article)

Modelling Dynamic 3D Human-Object Interactions: From Capture to Synthesis
Exploring Weight Bias and Negative Self-Evaluation in Patients with Mood Disorders: Insights from the BodyTalk Project,
Meneguzzo, P., Behrens, S. C., Pavan, C., Toffanin, T., Quiros-Ramirez, M. A., Black, M. J., Giel, K., Tenconi, E., Favaro, A.
Frontiers in Psychiatry, 15, Sec. Psychopathology, May 2024 (article)

The Poses for Equine Research Dataset (PFERD)
Li, C., Mellbin, Y., Krogager, J., Polikovsky, S., Holmberg, M., Ghorbani, N., Black, M. J., Kjellström, H., Zuffi, S., Hernlund, E.
Nature Scientific Data, 11, May 2024 (article)
InterCap: Joint Markerless 3D Tracking of Humans and Objects in Interaction from Multi-view RGB-D Images
Huang, Y., Taheri, O., Black, M. J., Tzionas, D.
International Journal of Computer Vision (IJCV), 2024 (article)

Self- and Interpersonal Contact in 3D Human Mesh Reconstruction
Natural Language Control for 3D Human Motion Synthesis

HMP: Hand Motion Priors for Pose and Shape Estimation from Video
Duran, E., Kocabas, M., Choutas, V., Fan, Z., Black, M. J.
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024 (article)
2023

FLARE: Fast learning of Animatable and Relightable Mesh Avatars
Bharadwaj, S., Zheng, Y., Hilliges, O., Black, M. J., Abrevaya, V. F.
ACM Transactions on Graphics, 42(6):204:1-204:15, December 2023 (article) Accepted
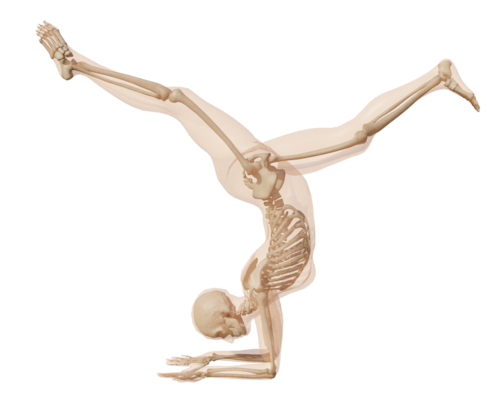
From Skin to Skeleton: Towards Biomechanically Accurate 3D Digital Humans
(Honorable Mention for Best Paper)
Keller, M., Werling, K., Shin, S., Delp, S., Pujades, S., Liu, C. K., Black, M. J.
ACM Transaction on Graphics (ToG), 42(6):253:1-253:15, December 2023 (article)

BARC: Breed-Augmented Regression Using Classification for 3D Dog Reconstruction from Images
Rueegg, N., Zuffi, S., Schindler, K., Black, M. J.
Int. J. of Comp. Vis. (IJCV), 131(8):1964–1979, August 2023 (article)

Virtual Reality Exposure to a Healthy Weight Body Is a Promising Adjunct Treatment for Anorexia Nervosa
Behrens, S. C., Tesch, J., Sun, P. J., Starke, S., Black, M. J., Schneider, H., Pruccoli, J., Zipfel, S., Giel, K. E.
Psychotherapy and Psychosomatics, 92(3):170-179, June 2023 (article)
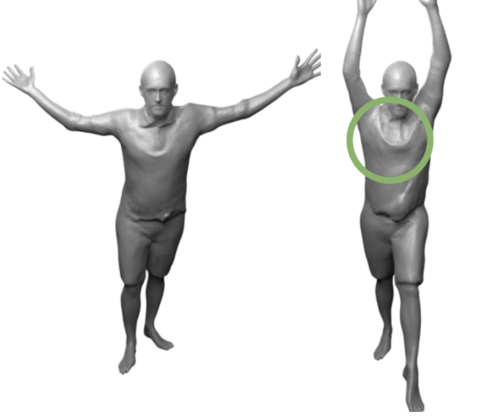
Fast-SNARF: A Fast Deformer for Articulated Neural Fields
Chen, X., Jiang, T., Song, J., Rietmann, M., Geiger, A., Black, M. J., Hilliges, O.
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), pages: 1-15, April 2023 (article)

SmartMocap: Joint Estimation of Human and Camera Motion Using Uncalibrated RGB Cameras
Saini, N., Huang, C. P., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, 8(6):3206-3213, 2023 (article)
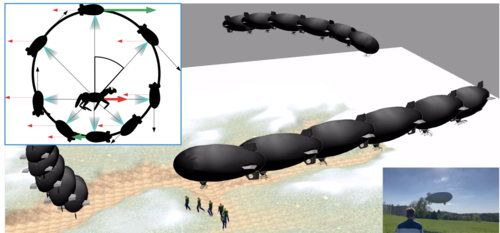
Viewpoint-Driven Formation Control of Airships for Cooperative Target Tracking
Price, E., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, 8(6):3653-3660, 2023 (article)
2022

Reconstructing Expressive 3D Humans from RGB Images
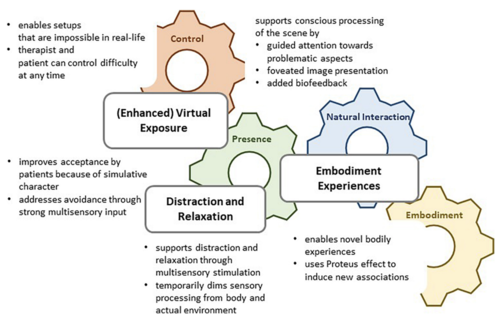
How immersive virtual reality can become a key tool to advance research and psychotherapy of eating and weight disorders
Behrens, S. C., Streuber, S., Keizer, A., Giel, K. E.
Frontiers in Psychiatry, 13, pages: 1011620, November 2022 (article)

iRotate: Active visual SLAM for omnidirectional robots
Bonetto, E., Goldschmid, P., Pabst, M., Black, M. J., Ahmad, A.
Robotics and Autonomous Systems, 154, pages: 104102, Elsevier, August 2022 (article)

AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
Saini, N., Bonetto, E., Price, E., Ahmad, A., Black, M. J.
IEEE Robotics and Automation Letters, 7(2):4805-4812, IEEE, April 2022, Also accepted and presented in the 2022 IEEE International Conference on Robotics and Automation (ICRA) (article)

Physical activity improves body image of sedentary adults. Exploring the roles of interoception and affective response
Srismith, D., Dierkes, K., Zipfel, S., Thiel, A., Sudeck, G., Giel, K. E., Behrens, S. C.
Current Psychology, Springer, 2022 (article) Accepted
2021
The neural coding of face and body orientation in occipitotemporal cortex
Foster, C., Zhao, M., Bolkart, T., Black, M. J., Bartels, A., Bülthoff, I.
NeuroImage, 246, pages: 118783, December 2021 (article)
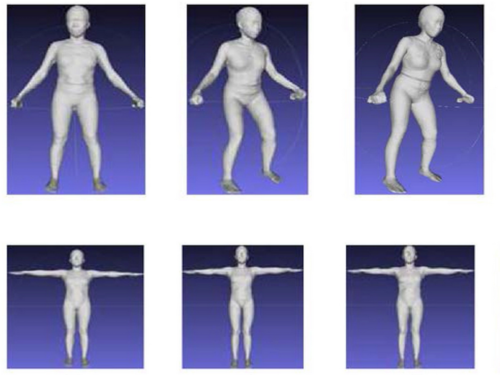
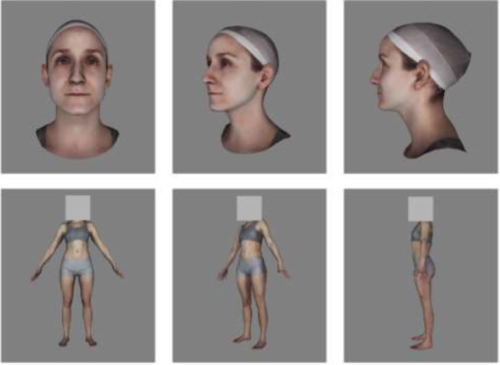
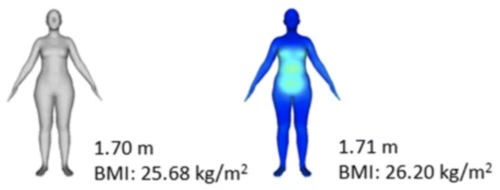
A pose-independent method for accurate and precise body composition from 3D optical scans
Wong, M. C., Ng, B. K., Tian, I., Sobhiyeh, S., Pagano, I., Dechenaud, M., Kennedy, S. F., Liu, Y. E., Kelly, N., Chow, D., Garber, A. K., Maskarinec, G., Pujades, S., Black, M. J., Curless, B., Heymsfield, S. B., Shepherd, J. A.
Obesity, 29(11):1835-1847, Wiley, November 2021 (article)
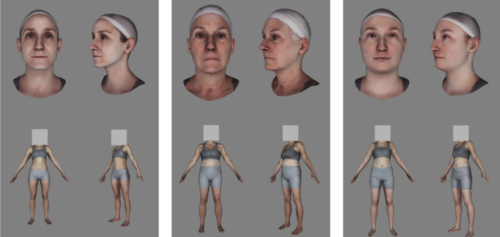
Separated and overlapping neural coding of face and body identity
Foster, C., Zhao, M., Bolkart, T., Black, M. J., Bartels, A., Bülthoff, I.
Human Brain Mapping, 42(13):4242-4260, September 2021 (article)
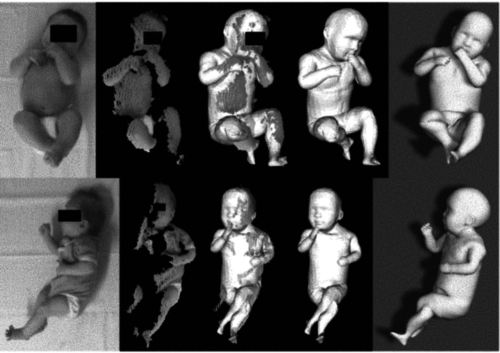
Skinned multi-infant linear body model
Hesse, N., Pujades, S., Romero, J., Black, M.
(US Patent 11,127,163, 2021), September 2021 (patent)
The role of sexual orientation in the relationships between body perception, body weight dissatisfaction, physical comparison, and eating psychopathology in the cisgender population
Meneguzzo, P., Collantoni, E., Bonello, E., Vergine, M., Behrens, S. C., Tenconi, E., Favaro, A.
Eating and Weight Disorders - Studies on Anorexia, Bulimia and Obesity , 26(6):1985-2000, Springer, August 2021 (article)

Learning an Animatable Detailed 3D Face Model from In-the-Wild Images
Feng, Y., Feng, H., Black, M. J., Bolkart, T.
ACM Transactions on Graphics, 40(4):88:1-88:13, August 2021 (article)
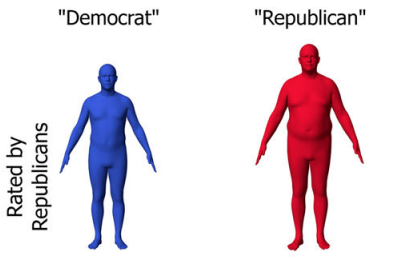
Red shape, blue shape: Political ideology influences the social perception of body shape
Quiros-Ramirez, M. A., Streuber, S., Black, M. J.
Nature Humanities and Social Sciences Communications, 8, pages: 148, June 2021 (article)

Weight bias and linguistic body representation in anorexia nervosa: Findings from the BodyTalk project
(Top Cited Article 2021-2022)
Behrens, S. C., Meneguzzo, P., Favaro, A., Teufel, M., Skoda, E., Lindner, M., Walder, L., Quiros-Ramirez, M. A., Zipfel, S., Mohler, B., Black, M., Giel, K. E.
European Eating Disorders Review, 29(2):204-215, Wiley, March 2021 (article)

Analyzing the Direction of Emotional Influence in Nonverbal Dyadic Communication: A Facial-Expression Study
Shadaydeh, M., Müller, L., Schneider, D., Thuemmel, M., Kessler, T., Denzler, J.
IEEE Access, 9, pages: 73780-73790, IEEE, 2021 (article)

Scientific Report 2016 - 2021
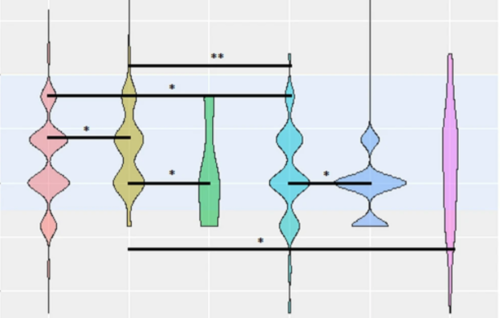
Body Image Disturbances and Weight Bias After Obesity Surgery: Semantic and Visual Evaluation in a Controlled Study, Findings from the BodyTalk Project
Meneguzzo, P., Behrens, S. C., Favaro, A., Tenconi, E., Vindigni, V., Teufel, M., Skoda, E., Lindner, M., Quiros-Ramirez, M. A., Mohler, B., Black, M., Zipfel, S., Giel, K. E., Pavan, C.
Obesity Surgery, 31(4):1625-1634, 2021 (article)
2020
Occlusion Boundary: A Formal Definition & Its Detection via Deep Exploration of Context
Wang, C., Fu, H., Tao, D., Black, M. J.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(5):2641-2656, November 2020 (article)

3D Morphable Face Models - Past, Present and Future
Egger, B., Smith, W. A. P., Tewari, A., Wuhrer, S., Zollhoefer, M., Beeler, T., Bernard, F., Bolkart, T., Kortylewski, A., Romdhani, S., Theobalt, C., Blanz, V., Vetter, T.
ACM Transactions on Graphics, 39(5):157, October 2020 (article)
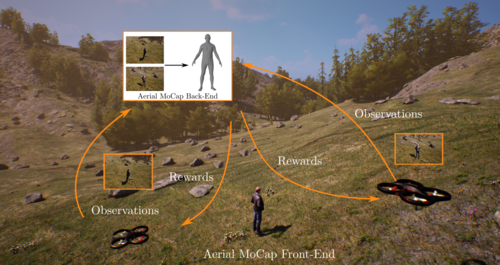
AirCapRL: Autonomous Aerial Human Motion Capture Using Deep Reinforcement Learning
Tallamraju, R., Saini, N., Bonetto, E., Pabst, M., Liu, Y. T., Black, M., Ahmad, A.
IEEE Robotics and Automation Letters, 5(4):6678-6685, IEEE, October 2020, Also accepted and presented in the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). (article)

Analysis of motor development within the first year of life: 3-D motion tracking without markers for early detection of developmental disorders
Parisi, C., Hesse, N., Tacke, U., Rocamora, S. P., Blaschek, A., Hadders-Algra, M., Black, M. J., Heinen, F., Müller-Felber, W., Schroeder, A. S.
Bundesgesundheitsblatt - Gesundheitsforschung - Gesundheitsschutz, 63(7):881–890, July 2020 (article)
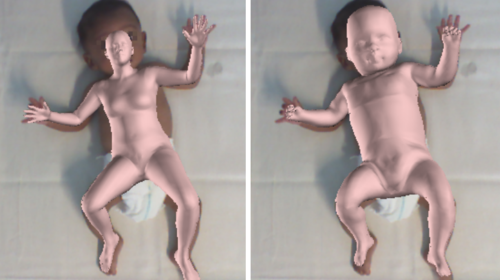
Learning and Tracking the 3D Body Shape of Freely Moving Infants from RGB-D sequences
Hesse, N., Pujades, S., Black, M., Arens, M., Hofmann, U., Schroeder, S.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 42(10):2540-2551, 2020 (article)
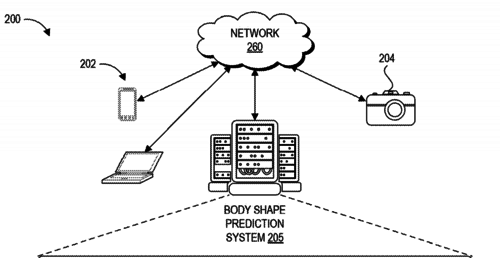
Machine learning systems and methods of estimating body shape from images
Black, M., Rachlin, E., Heron, N., Loper, M., Weiss, A., Hu, K., Hinkle, T., Kristiansen, M.
(US Patent 10,679,046), June 2020 (patent)

General Movement Assessment from videos of computed 3D infant body models is equally effective compared to conventional RGB Video rating
Schroeder, S., Hesse, N., Weinberger, R., Tacke, U., Gerstl, L., Hilgendorff, A., Heinen, F., Arens, M., Bodensteiner, C., Dijkstra, L. J., Pujades, S., Black, M., Hadders-Algra, M.
Early Human Development, 144, pages: 104967, May 2020 (article)

Real Time Trajectory Prediction Using Deep Conditional Generative Models
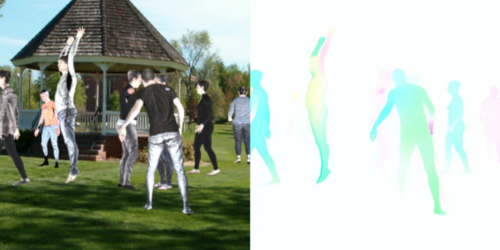
Learning Multi-Human Optical Flow
Ranjan, A., Hoffmann, D. T., Tzionas, D., Tang, S., Romero, J., Black, M. J.
International Journal of Computer Vision (IJCV), 128(4):873-890, April 2020 (article)
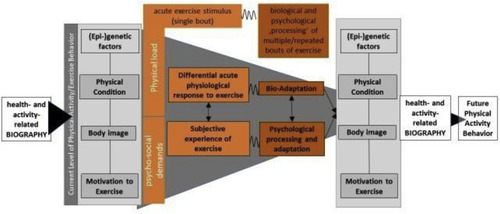
The iReAct study - A biopsychosocial analysis of the individual response to physical activity
Thiel, A., Sudeck, G., Gropper, H., Maturana, F. M., Schubert, T., Srismith, D., Widmann, M., Behrens, S., Martus, P., Munz, B., Giel, K., Zipfel, S., Niess, A. M.
Contemporary Clinical Trials Communications , 17, pages: 100508, March 2020 (article)
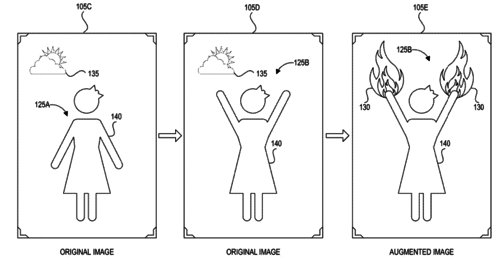
Machine learning systems and methods for augmenting images
Black, M., Rachlin, E., Lee, E., Heron, N., Loper, M., Weiss, A., Smith, D.
(US Patent 10,529,137 B1), January 2020 (patent)

Influence of Physical Activity Interventions on Body Representation: A Systematic Review
Srismith, D., Wider, L., Wong, H. Y., Zipfel, S., Thiel, A., Giel, K. E., Behrens, S. C.
Frontiers in Psychiatry, 11, pages: 99, 2020 (article)
2019

Towards Geometric Understanding of Motion
The motion of the world is inherently dependent on the spatial structure of the world and its geometry. Therefore, classical optical flow methods try to model this geometry to solve for the motion. However, recent deep learning methods take a completely different approach. They try to predict optical flow by learning from labelled data. Although deep networks have shown state-of-the-art performance on classification problems in computer vision, they have not been as effective in solving optical flow. The key reason is that deep learning methods do not explicitly model the structure of the world in a neural network, and instead expect the network to learn about the structure from data. We hypothesize that it is difficult for a network to learn about motion without any constraint on the structure of the world. Therefore, we explore several approaches to explicitly model the geometry of the world and its spatial structure in deep neural networks.
The spatial structure in images can be captured by representing it at multiple scales. To represent multiple scales of images in deep neural nets, we introduce a Spatial Pyramid Network (SpyNet). Such a network can leverage global information for estimating large motions and local information for estimating small motions. We show that SpyNet significantly improves over previous optical flow networks while also being the smallest and fastest neural network for motion estimation. SPyNet achieves a 97% reduction in model parameters over previous methods and is more accurate.
The spatial structure of the world extends to people and their motion. Humans have a very well-defined structure, and this information is useful in estimating optical flow for humans. To leverage this information, we create a synthetic dataset for human optical flow using a statistical human body model and motion capture sequences. We use this dataset to train deep networks and see significant improvement in the ability of the networks to estimate human optical flow.
The structure and geometry of the world affects the motion. Therefore, learning about the structure of the scene together with the motion can benefit both problems. To facilitate this, we introduce Competitive Collaboration, where several neural networks are constrained by geometry and can jointly learn about structure and motion in the scene without any labels. To this end, we show that jointly learning single view depth prediction, camera motion, optical flow and motion segmentation using Competitive Collaboration achieves state-of-the-art results among unsupervised approaches.
Our findings provide support for our hypothesis that explicit constraints on structure and geometry of the world lead to better methods for motion estimation.
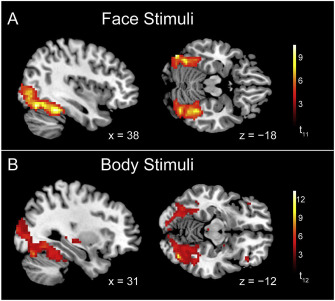
Decoding subcategories of human bodies from both body- and face-responsive cortical regions
Foster, C., Zhao, M., Romero, J., Black, M. J., Mohler, B. J., Bartels, A., Bülthoff, I.
NeuroImage, 202(15):116085, November 2019 (article)
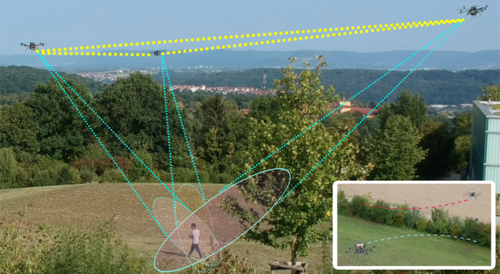
Active Perception based Formation Control for Multiple Aerial Vehicles
Tallamraju, R., Price, E., Ludwig, R., Karlapalem, K., Bülthoff, H. H., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, Robotics and Automation Letters, 4(4):4491-4498, IEEE, October 2019 (article)
Method for providing a three dimensional body model
Loper, M., Mahmood, N., Black, M.
September 2019, U.S.~Patent 10,417,818 (patent)

Decoding the Viewpoint and Identity of Faces and Bodies
Foster, C., Zhao, M., Bolkart, T., Black, M., Bartels, A., Bülthoff, I.
Journal of Vision, 19(10): 54c, pages: 54-55, Arvo Journals, September 2019 (article)