2025

OpenCapBench: A Benchmark to Bridge Pose Estimation and Biomechanics
Gozlan, Y., Falisse, A., Uhlrich, S., Gatti, A., Black, M., Chaudhari, A.
In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , February 2025 (inproceedings)
2024

SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Baert, K., Bharadwaj, S., Castan, F., Maujean, B., Christie, M., Abrevaya, V., Boukhayma, A.
In SIGGRAPH Asia 2024 Conference Proceedings, December 2024 (inproceedings) Accepted
PuzzleAvatar: Assembling 3D Avatars from Personal Albums
Xiu, Y., Liu, Z., Tzionas, D., Black, M. J.
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published
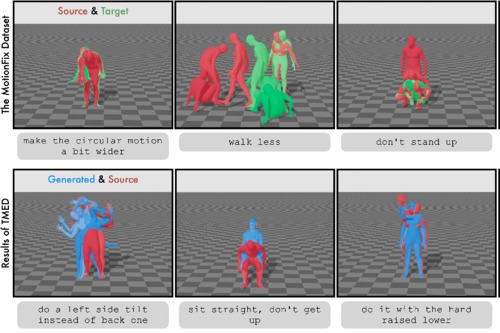
MotionFix: Text-Driven 3D Human Motion Editing
Athanasiou, N., Cseke, A., Diomataris, M., Black, M. J., Varol, G.
In SIGGRAPH Asia 2024 Conference Proceedings, ACM, December 2024 (inproceedings) To be published

StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y., Dong, Z., Bo, L., Xiu, Y., Han, X.
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published

Human Hair Reconstruction with Strand-Aligned 3D Gaussians
Zakharov, E., Sklyarova, V., Black, M. J., Nam, G., Thies, J., Hilliges, O.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)

Stable Video Portraits
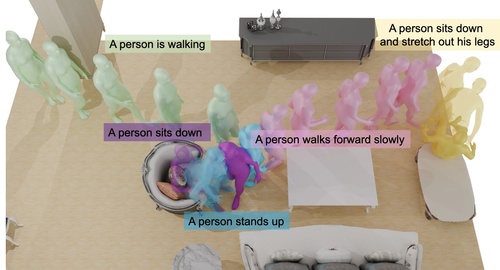
Generating Human Interaction Motions in Scenes with Text Control
Yi, H., Thies, J., Black, M. J., Peng, X. B., Rempe, D.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)
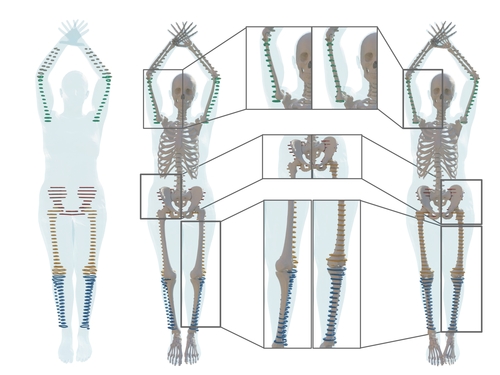
On predicting 3D bone locations inside the human body
Dakri, A., Arora, V., Challier, L., Keller, M., Black, M. J., Pujades, S.
In 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), October 2024 (inproceedings)

Synthesizing Environment-Specific People in Photographs
Ostrek, M., O’Sullivan, C., Black, M., Thies, J.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings) Accepted

Explorative Inbetweening of Time and Space
Feng, H., Ding, Z., Xia, Z., Niklaus, S., Fernandez Abrevaya, V., Black, M. J., Zhang, X.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)
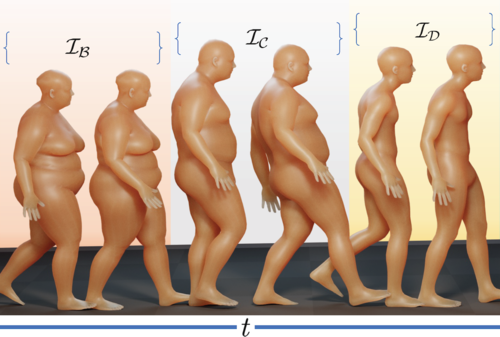
HUMOS: Human Motion Model Conditioned on Body Shape
Tripathi, S., Taheri, O., Lassner, C., Black, M. J., Holden, D., Stoll, C.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)
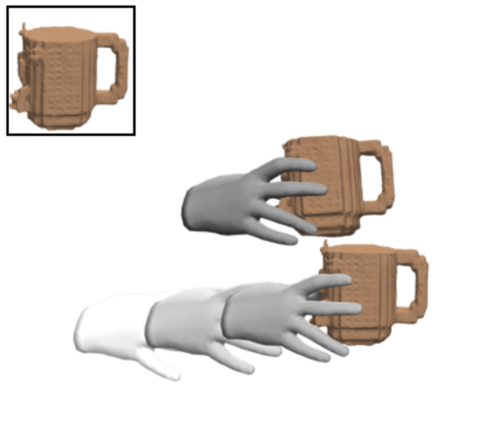
GraspXL: Generating Grasping Motions for Diverse Objects at Scale
Zhang, H., Christen, S., Fan, Z., Hilliges, O., Song, J.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, September 2024 (inproceedings) Accepted

Leveraging Unpaired Data for the Creation of Controllable Digital Humans
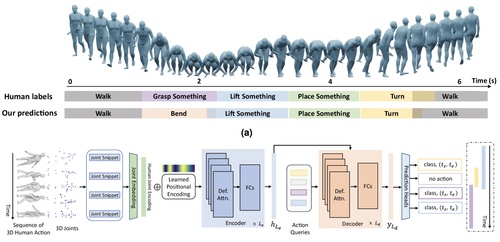
Localization and recognition of human action in 3D using transformers
Sun, J., Huang, L., Hongsong Wang, C. Z. J. Q., Islam, M. T., Xie, E., Zhou, B., Xing, L., Chandrasekaran, A., Black, M. J.
Nature Communications Engineering , 13(125), September 2024 (article)

Realistic Digital Human Characters: Challenges, Models and Algorithms

Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Fan, Z., Ohkawa, T., Yang, L., Lin, N., Zhou, Z., Zhou, S., Liang, J., Gao, Z., Zhang, X., Zhang, X., Li, F., Zheng, L., Lu, F., Zeid, K. A., Leibe, B., On, J., Baek, S., Prakash, A., Gupta, S., He, K., Sato, Y., Hilliges, O., Chang, H. J., Yao, A.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, September 2024 (inproceedings) Accepted
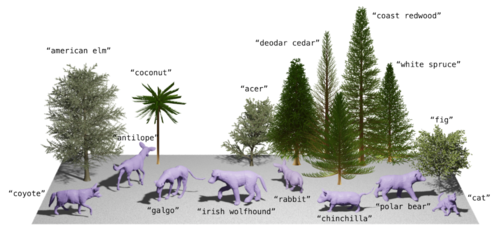
AWOL: Analysis WithOut synthesis using Language
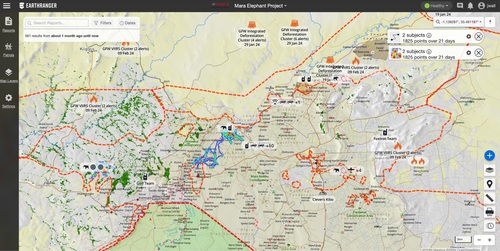
EarthRanger: An Open-Source Platform for Ecosystem Monitoring, Research, and Management
Wall, J., Lefcourt, J., Jones, C., Doehring, C., O’Neill, D., Schneider, D., Steward, J., Krautwurst, J., Wong, T., Jones, B., Goodfellow, K., Schmitt, T., Gobush, K., Douglas-Hamilton, I., Pope, F., Schmidt, E., Palmer, J., Stokes, E., Reid, A., Elbroch, M. L., Kulits, P., Villeneuve, C., Matsanza, V., Clinning, G., Oort, J. V., Denninger-Snyder, K., Daati, A. P., Gold, W., Cunliffe, S., Craig, B., Cork, B., Burden, G., Goss, M., Hahn, N., Carroll, S., Gitonga, E., Rao, R., Stabach, J., Broin, F. D., Omondi, P., Wittemyer, G.
Methods in Ecology and Evolution, 13, British Ecological Society, September 2024 (article)
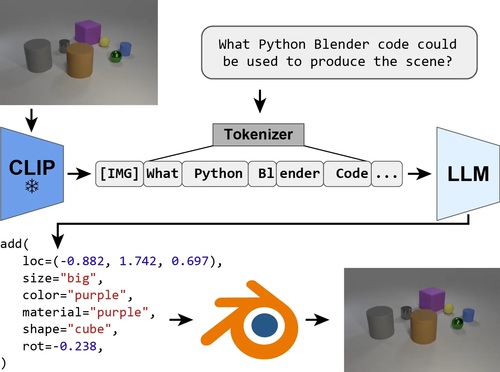
Re-Thinking Inverse Graphics with Large Language Models
Kulits, P., Feng, H., Liu, W., Abrevaya, V., Black, M. J.
Transactions on Machine Learning Research, August 2024 (article)

ContourCraft: Learning to Resolve Intersections in Neural Multi-Garment Simulations
Grigorev, A., Becherini, G., Black, M., Hilliges, O., Thomaszewski, B.
In ACM SIGGRAPH 2024 Conference Papers, pages: 1-10, SIGGRAPH ’24, Association for Computing Machinery, New York, NY, USA, July 2024 (inproceedings)

Modelling Dynamic 3D Human-Object Interactions: From Capture to Synthesis

Airship Formations for Animal Motion Capture and Behavior Analysis
(Best Paper)
Proceedings 2nd International Conference on Design and Engineering of Lighter-Than-Air systems (DELTAS2024), June 2024 (conference) Accepted

EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling
Liu, H., Zhu, Z., Becherini, G., Peng, Y., Su, M., Zhou, Y., Zhe, X., Iwamoto, N., Zheng, B., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

HUGS: Human Gaussian Splats
Kocabas, M., Chang, R., Gabriel, J., Tuzel, O., Ranjan, A.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
(Highlight)
Fan, Z., Parelli, M., Kadoglou, M. E., Kocabas, M., Chen, X., Black, M. J., Hilliges, O.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)
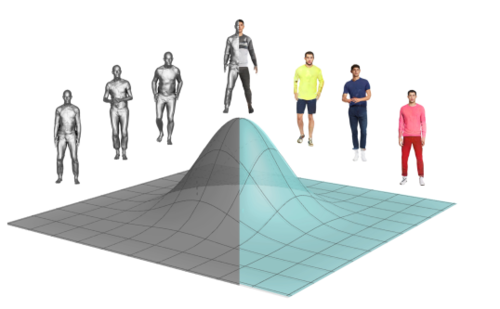
SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes
Sanyal, S., Ghosh, P., Yang, J., Black, M. J., Thies, J., Bolkart, T.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 2362-2371, June 2024 (inproceedings)
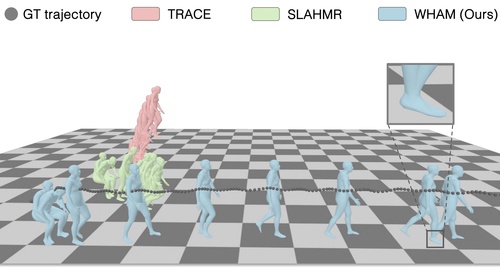
WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion
Shin, S., Kim, J., Halilaj, E., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

Text-Conditioned Generative Model of 3D Strand-based Human Hairstyles
Sklyarova, V., Zakharov, E., Hilliges, O., Black, M. J., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

4D-DRESS: A 4D Dataset of Real-World Human Clothing With Semantic Annotations
Wang, W., Ho, H., Guo, C., Rong, B., Grigorev, A., Song, J., Zarate, J. J., Hilliges, O.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)
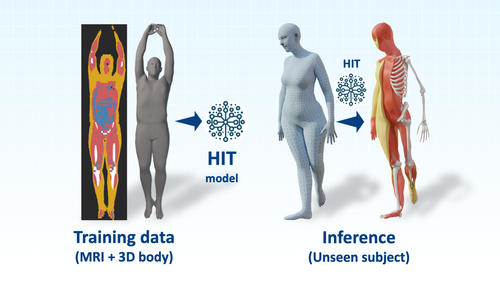
HIT: Estimating Internal Human Implicit Tissues from the Body Surface
Keller, M., Arora, V., Dakri, A., Chandhok, S., Machann, J., Fritsche, A., Black, M. J., Pujades, S.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 3480-3490, June 2024 (inproceedings)

WANDR: Intention-guided Human Motion Generation
Diomataris, M., Athanasiou, N., Taheri, O., Wang, X., Hilliges, O., Black, M. J.
In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages: 927,936, IEEE Computer Society, June 2024 (inproceedings)
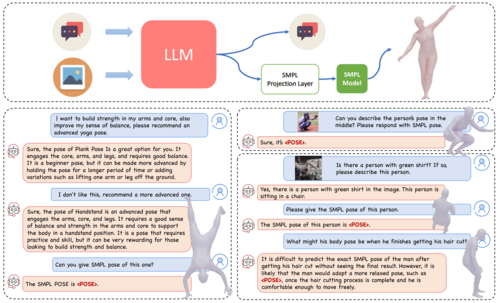
ChatPose: Chatting about 3D Human Pose
Feng, Y., Lin, J., Dwivedi, S. K., Sun, Y., Patel, P., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

Generative Proxemics: A Prior for 3D Social Interaction from Images
Müller, L., Ye, V., Pavlakos, G., Black, M., Kanazawa, A.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

VAREN: Very Accurate and Realistic Equine Network
Zuffi, S., Mellbin, Y., Li, C., Hoeschle, M., Kjellstrom, H., Polikovsky, S., Hernlund, E., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

MonoHair: High-Fidelity Hair Modeling from a Monocular Video
(Oral)
Wu, K., Yang, L., Kuang, Z., Feng, Y., Han, X., Shen, Y., Fu, H., Zhou, K., Zheng, Y.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)

AMUSE: Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Chhatre, K., Daněček, R., Athanasiou, N., Becherini, G., Peters, C., Black, M. J., Bolkart, T.
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages: 1942-1953, June 2024 (inproceedings)
Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation
Petrovich, M., Litany, O., Iqbal, U., Black, M. J., Varol, G., Peng, X. B., Rempe, D.
In CVPR Workshop on Human Motion Generation, Seattle, June 2024 (inproceedings)

A Unified Approach for Text- and Image-guided 4D Scene Generation
Zheng, Y., Li, X., Nagano, K., Liu, S., Hilliges, O., Mello, S. D.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)
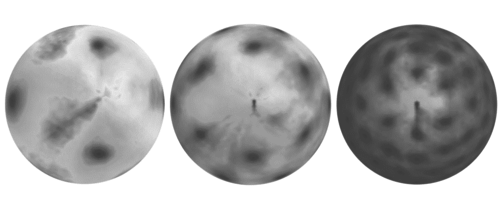
Neuropostors: Neural Geometry-aware 3D Crowd Character Impostors
Ostrek, M., Mitra, N. J., O’Sullivan, C.
In 2024 27th International Conference on Pattern Recognition (ICPR), Springer, June 2024 (inproceedings) Accepted

Real-time Monocular Full-body Capture in World Space via Sequential Proxy-to-Motion Learning
Zhang, H., Zhang, Y., Hu, L., Zhang, J., Yi, H., Zhang, S., Liu, Y.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)
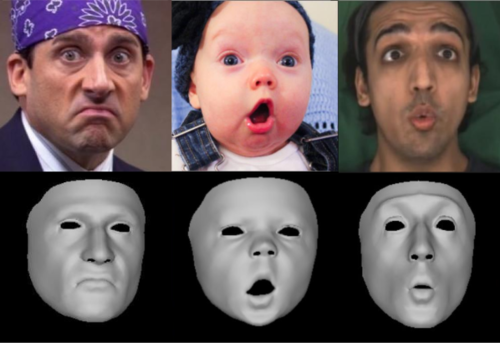
SMIRK: 3D Facial Expressions through Analysis-by-Neural-Synthesis
Retsinas, G., Filntisis, P. P., Danecek, R., Abrevaya, V. F., Roussos, A., Bolkart, T., Maragos, P.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024 (inproceedings)
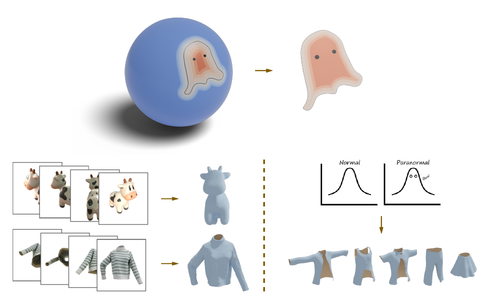
Ghost on the Shell: An Expressive Representation of General 3D Shapes
Liu, Z., Feng, Y., Xiu, Y., Liu, W., Paull, L., Black, M. J., Schölkopf, B.
In Proceedings of the Twelfth International Conference on Learning Representations, May 2024 (inproceedings)
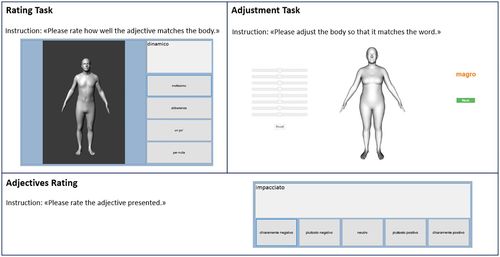
Exploring Weight Bias and Negative Self-Evaluation in Patients with Mood Disorders: Insights from the BodyTalk Project,
Meneguzzo, P., Behrens, S. C., Pavan, C., Toffanin, T., Quiros-Ramirez, M. A., Black, M. J., Giel, K., Tenconi, E., Favaro, A.
Frontiers in Psychiatry, 15, Sec. Psychopathology, May 2024 (article)
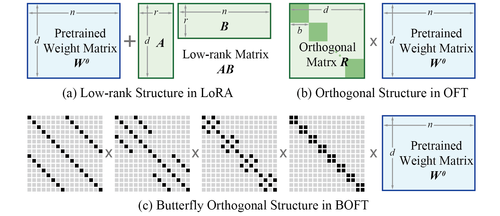
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Liu, W., Qiu, Z., Feng, Y., Xiu, Y., Xue, Y., Yu, L., Feng, H., Liu, Z., Heo, J., Peng, S., Wen, Y., Black, M. J., Weller, A., Schölkopf, B.
In Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (inproceedings)

The Poses for Equine Research Dataset (PFERD)
Li, C., Mellbin, Y., Krogager, J., Polikovsky, S., Holmberg, M., Ghorbani, N., Black, M. J., Kjellström, H., Zuffi, S., Hernlund, E.
Nature Scientific Data, 11, May 2024 (article)

TADA! Text to Animatable Digital Avatars
Liao, T., Yi, H., Xiu, Y., Tang, J., Huang, Y., Thies, J., Black, M. J.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings) Accepted

POCO: 3D Pose and Shape Estimation using Confidence
Dwivedi, S. K., Schmid, C., Yi, H., Black, M. J., Tzionas, D.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings)

PACE: Human and Camera Motion Estimation from in-the-wild Videos
Kocabas, M., Yuan, Y., Molchanov, P., Guo, Y., Black, M. J., Hilliges, O., Kautz, J., Iqbal, U.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings)
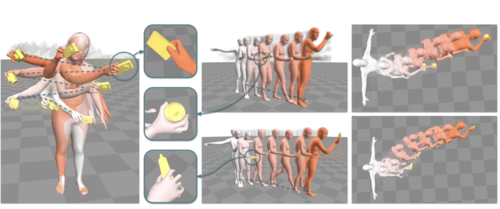
Physically plausible full-body hand-object interaction synthesis
Braun, J., Christen, S., Kocabas, M., Aksan, E., Hilliges, O.
In International Conference on 3D Vision (3DV 2024), March 2024 (inproceedings)