2019
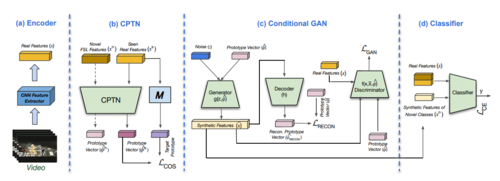
ProtoGAN: Towards Few Shot Learning for Action Recognition
Dwivedi, S. K., Gupta, V., Mitra, R., Ahmed, S., Jain, A.
Proc. International Conference on Computer Vision (ICCV) Workshops, October 2019 (manual)
2017
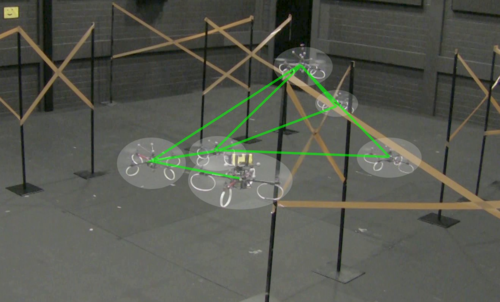
Decentralized Simultaneous Multi-target Exploration using a Connected Network of Multiple Robots
Nestmeyer, T., Robuffo Giordano, P., Bülthoff, H. H., Franchi, A.
In pages: 989-1011, Autonomous Robots, 2017 (incollection)
2014

Advanced Structured Prediction
Nowozin, S., Gehler, P. V., Jancsary, J., Lampert, C. H.
Advanced Structured Prediction, pages: 432, Neural Information Processing Series, MIT Press, November 2014 (book)

Human Pose Estimation from Video and Inertial Sensors
Simulated Annealing
2013
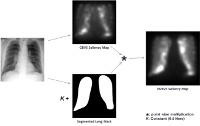
A Study of X-Ray Image Perception for Pneumoconiosis Detection

Image Gradient Based Level Set Methods in 2D and 3D
Xie, X., Yeo, S. Y., Mirmehdi, M., Sazonov, I., Nithiarasu, P.
In Deformation Models: Tracking, Animation and Applications, pages: 101-120, 0, (Editors: Manuel González Hidalgo and Arnau Mir Torres and Javier Varona Gómez), Springer, 2013 (inbook)
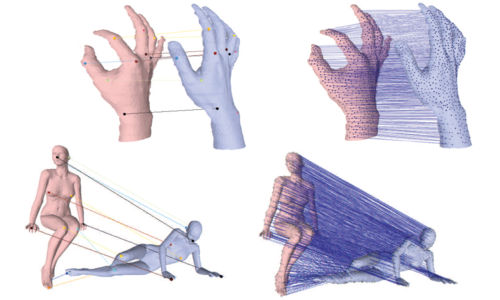
Modeling Shapes with Higher-Order Graphs: Theory and Applications
Wang, C., Zeng, Y., Samaras, D., Paragios, N.
In Shape Perception in Human and Computer Vision: An Interdisciplinary Perspective, (Editors: Zygmunt Pizlo and Sven Dickinson), Springer, 2013 (incollection)

Class-Specific Hough Forests for Object Detection
Gall, J., Lempitsky, V.
In Decision Forests for Computer Vision and Medical Image Analysis, pages: 143-157, 11, (Editors: Criminisi, A. and Shotton, J.), Springer, 2013 (incollection)
2012
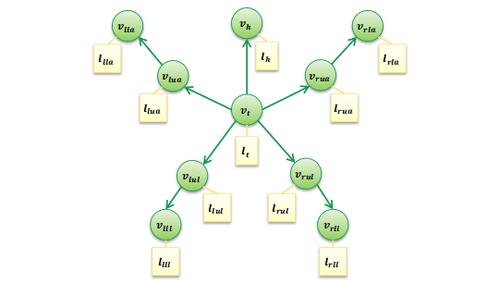
An Analysis of Successful Approaches to Human Pose Estimation

Exploiting pedestrian interaction via global optimization and social behaviors
Leal-Taixé, L., Pons-Moll, G., Rosenhahn, B.
In Theoretic Foundations of Computer Vision: Outdoor and Large-Scale Real-World Scene Analysis, Springer, April 2012 (incollection)
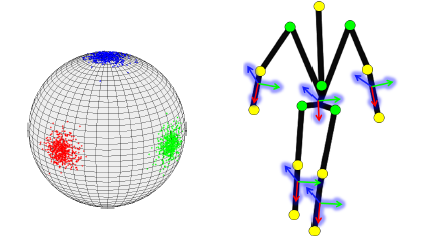
Data-driven Manifolds for Outdoor Motion Capture
Pons-Moll, G., Leal-Taix’e, L., Gall, J., Rosenhahn, B.
In Outdoor and Large-Scale Real-World Scene Analysis, 7474, pages: 305-328, LNCS, (Editors: Dellaert, Frank and Frahm, Jan-Michael and Pollefeys, Marc and Rosenhahn, Bodo and Leal-Taix’e, Laura), Springer, 2012 (incollection)
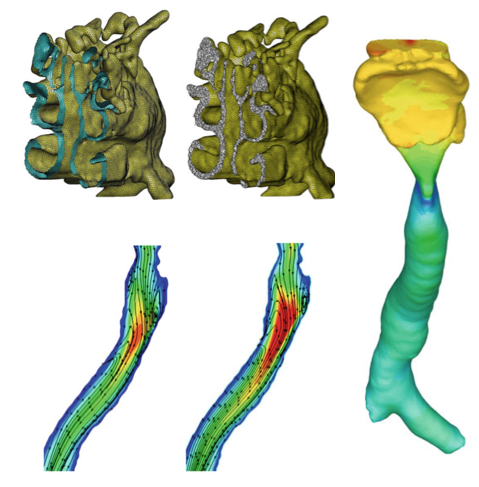
Scan-Based Flow Modelling in Human Upper Airways
Perumal Nithiarasu, I. S., Yeo, S. Y.
In Patient-Specific Modeling in Tomorrow’s Medicine, pages: 241 - 280, 0, (Editors: Amit Gefen), Springer, 2012 (inbook)
An Introduction to Random Forests for Multi-class Object Detection
Gall, J., Razavi, N., van Gool, L.
In Outdoor and Large-Scale Real-World Scene Analysis, 7474, pages: 243-263, LNCS, (Editors: Dellaert, Frank and Frahm, Jan-Michael and Pollefeys, Marc and Rosenhahn, Bodo and Leal-Taix’e, Laura), Springer, 2012 (incollection)

Consumer Depth Cameras for Computer Vision - Research Topics and Applications
Fossati, A., Gall, J., Grabner, H., Ren, X., Konolige, K.
Advances in Computer Vision and Pattern Recognition, Springer, 2012 (book)

Home 3D body scans from noisy image and range data
Weiss, A., Hirshberg, D., Black, M. J.
In Consumer Depth Cameras for Computer Vision: Research Topics and Applications, pages: 99-118, 6, (Editors: Andrea Fossati and Juergen Gall and Helmut Grabner and Xiaofeng Ren and Kurt Konolige), Springer-Verlag, 2012 (incollection)
2011

Fields of experts
Roth, S., Black, M. J.
In Markov Random Fields for Vision and Image Processing, pages: 297-310, (Editors: Blake, A. and Kohli, P. and Rother, C.), MIT Press, 2011 (incollection)

Steerable random fields for image restoration and inpainting
Roth, S., Black, M. J.
In Markov Random Fields for Vision and Image Processing, pages: 377-387, (Editors: Blake, A. and Kohli, P. and Rother, C.), MIT Press, 2011 (incollection)

Benchmark datasets for pose estimation and tracking
Andriluka, M., Sigal, L., Black, M. J.
In Visual Analysis of Humans: Looking at People, pages: 253-274, (Editors: Moesland and Hilton and Kr"uger and Sigal), Springer-Verlag, London, 2011 (incollection)
Model-Based Pose Estimation
Pons-Moll, G., Rosenhahn, B.
In Visual Analysis of Humans: Looking at People, pages: 139-170, 9, (Editors: T. Moeslund, A. Hilton, V. Krueger, L. Sigal), Springer, 2011 (inbook)
2009

An introduction to Kernel Learning Algorithms
Visual Object Discovery
Sinha, P., Balas, B., Ostrovsky, Y., Wulff, J.
In Object Categorization: Computer and Human Vision Perspectives, pages: 301-323, (Editors: S. J. Dickinson, A. Leonardis, B. Schiele, M.J. Tarr), Cambridge University Press, 2009 (inbook)
2008

GNU Octave Manual Version 3
Eaton, J. W., Bateman, D., Hauberg, S.
Network Theory Ltd., October 2008 (book)
2007
Probabilistically modeling and decoding neural population activity in motor cortex
Black, M. J., Donoghue, J. P.
In Toward Brain-Computer Interfacing, pages: 147-159, (Editors: Dornhege, G. and del R. Millan, J. and Hinterberger, T. and McFarland, D. and Muller, K.-R.), MIT Press, London, 2007 (incollection)
2006
Products of “Edge-perts”
Gehler, P., Welling, M.
In Advances in Neural Information Processing Systems 18, pages: 419-426, (Editors: Weiss, Y. and Sch"olkopf, B. and Platt, J.), MIT Press, Cambridge, MA, 2006 (incollection)
2004
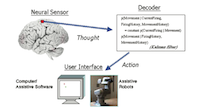
Development of neural motor prostheses for humans
Donoghue, J., Nurmikko, A., Friehs, G., Black, M.
In Advances in Clinical Neurophysiology, (Editors: Hallett, M. and Phillips, L.H. and Schomer, D.L. and Massey, J.M.), Supplements to Clinical Neurophysiology Vol. 57, 2004 (incollection)
2002

Bayesian Inference of Visual Motion Boundaries
Fleet, D. J., Black, M. J., Nestares, O.
In Exploring Artificial Intelligence in the New Millennium, pages: 139-174, (Editors: Lakemeyer, G. and Nebel, B.), Morgan Kaufmann Pub., July 2002 (incollection)
1999

Artscience Sciencart
Black, M. J., Levy, D., PamelaZ,
In Art and Innovation: The Xerox PARC Artist-in-Residence Program, pages: 244-300, (Editors: Harris, C.), MIT-Press, 1999 (incollection)
1998

Looking at people in action - An overview
Yacoob, Y., Davis, L. S., Black, M., Gavrila, D., Horprasert, T., Morimoto, C.
In Computer Vision for Human–Machine Interaction, (Editors: R. Cipolla and A. Pentland), Cambridge University Press, 1998 (incollection)
1997

Recognizing human motion using parameterized models of optical flow
Black, M. J., Yacoob, Y., Ju, X. S.
In Motion-Based Recognition, pages: 245-269, (Editors: Mubarak Shah and Ramesh Jain,), Kluwer Academic Publishers, Boston, MA, 1997 (incollection)
1993

Mixture models for optical flow computation
Jepson, A., Black, M.
In Partitioning Data Sets, DIMACS Workshop, pages: 271-286, (Editors: Ingemar Cox, Pierre Hansen, and Bela Julesz), AMS Pub, Providence, RI., April 1993 (incollection)