We are More than Our Joints: Predicting how 3D Bodies Move
2021
Conference Paper
ps
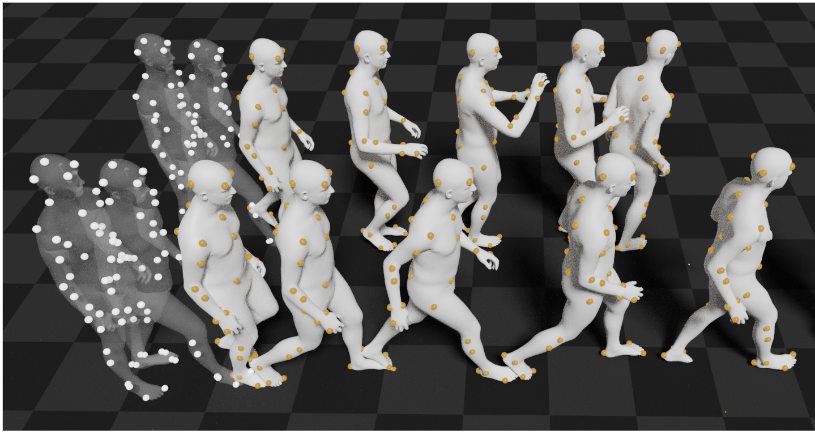
A key step towards understanding human behavior is the prediction of 3D human motion. Successful solutions have many applications in human tracking, HCI, and graphics. Most previous work focuses on predicting a time series of future 3D joint locations given a sequence 3D joints from the past. This Euclidean formulation generally works better than predicting pose in terms of joint rotations. Body joint locations, however, do not fully constrain 3D human pose, leaving degrees of freedom (like rotation about a limb) undefined. Note that 3D joints can be viewed as a sparse point cloud. Thus the problem of human motion prediction can be seen as a problem of point cloud prediction. With this observation, we instead predict a sparse set of locations on the body surface that correspond to motion capture markers. Given such markers, we fit a parametric body model to recover the 3D body of the person. These sparse surface markers also carry detailed information about human movement that is not present in the joints, increasing the naturalness of the predicted motions. Using the AMASS dataset, we train MOJO (More than Our JOints), which is a novel variational autoencoder with a latent DCT space that generates motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit the SMPL-X body model to the predictions at each time step, projecting the solution back onto the space of valid bodies, before propagating the new markers in time. Quantitative and qualitative experiments show that our approach produces state-of-the-art results and realistic 3D body animations. The code is available for research purposes at https://yz-cnsdqz.github.io/MOJO/MOJO.html.
| Author(s): | Yan Zhang and Michael J. Black and Siyu Tang |
| Book Title: | 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021) |
| Pages: | 3371--3381 |
| Year: | 2021 |
| Month: | June |
| Publisher: | IEEE |
| Department(s): | Perceiving Systems |
| Research Project(s): |
Modeling Human Movement
|
| Bibtex Type: | Conference Paper (inproceedings) |
| Paper Type: | Conference |
| DOI: | 10.1109/CVPR46437.2021.00338 |
| Event Name: | IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021) |
| Event Place: | Virtual |
| Address: | Piscataway, NJ |
| ISBN: | 978-1-6654-4510-8 |
| State: | Published |
| Links: |
code
arXiv |
|
BibTex @inproceedings{Zhang:CVPR:2021,
title = {We are More than Our Joints: Predicting how {3D} Bodies Move},
author = {Zhang, Yan and Black, Michael J. and Tang, Siyu},
booktitle = {2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021)},
pages = {3371--3381},
publisher = {IEEE},
address = {Piscataway, NJ},
month = jun,
year = {2021},
doi = {10.1109/CVPR46437.2021.00338},
month_numeric = {6}
}
|
|