MOJO: We are More than Our Joints
2021-06-18
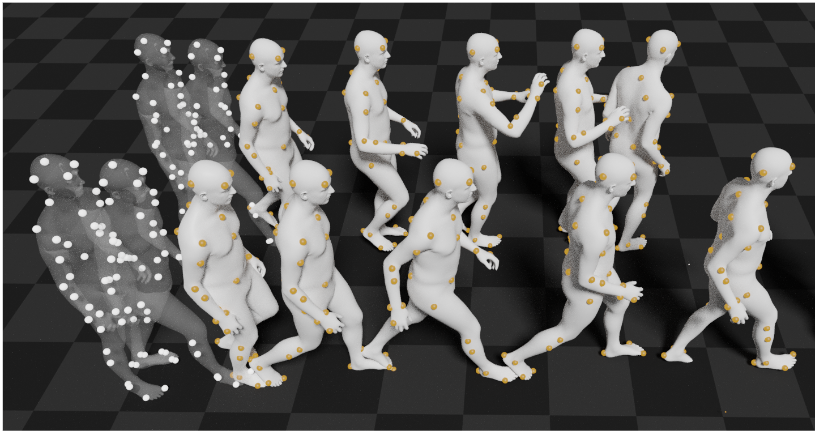
MOJO (More than Our JOints) is a novel variational autoencoder with a latent DCT space that generates 3D human motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit the SMPL-X body model to the predictions at each time step, projecting the solution back onto the space of valid bodies, before propagating the new markers in time. Quantitative and qualitative experiments show that our approach produces state-of-the-art results and realistic 3D body animations.
MOJO (More than Our JOints) is a novel variational autoencoder with a latent DCT space that generates 3D human motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit the SMPL-X body model to the predictions at each time step, projecting the solution back onto the space of valid bodies, before propagating the new markers in time. Quantitative and qualitative experiments show that our approach produces state-of-the-art results and realistic 3D body animations.
| Author(s): | Yan Zhang, Michael J. Black, and Siyu Tang |
| Department(s): |
Perceiving Systems |
| Publication(s): |
We are More than Our Joints: Predicting how {3D} Bodies Move
|
| Authors: | Yan Zhang, Michael J. Black, and Siyu Tang |
| Release Date: | 2021-06-18 |
| Repository: | https://yz-cnsdqz.github.io/MOJO/MOJO.html |