ICON: Implicit Clothed humans Obtained from Normals
2022
Conference Paper
ps
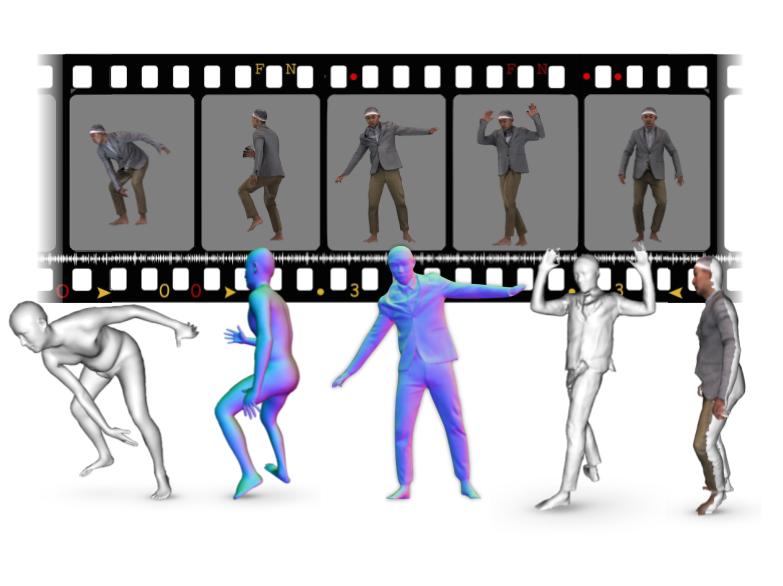
Current methods for learning realistic and animatable 3D clothed avatars need either posed 3D scans or 2D images with carefully controlled user poses. In contrast, our goal is to learn the avatar from only 2D images of people in unconstrained poses. Given a set of images, our method estimates a detailed 3D surface from each image and then combines these into an animatable avatar. Implicit functions are well suited to the first task, as they can capture details like hair or clothes. Current methods, however, are not robust to varied human poses and often produce 3D surfaces with broken or disembodied limbs, missing details, or non-human shapes. The problem is that these methods use global feature encoders that are sensitive to global pose. To address this, we propose ICON ("Implicit Clothed humans Obtained from Normals"), which uses local features, instead. ICON has two main modules, both of which exploit the SMPL(-X) body model. First, ICON infers detailed clothed-human normals (front/back) conditioned on the SMPL(-X) normals. Second, a visibility-aware implicit surface regressor produces an iso-surface of a human occupancy field. Importantly, at inference time, a feedback loop alternates between refining the SMPL(-X) mesh using the inferred clothed normals and then refining the normals. Given multiple reconstructed frames of a subject in varied poses, we use SCANimate to produce an animatable avatar from them. Evaluation on the AGORA and CAPE datasets shows that ICON outperforms the state of the art in reconstruction, even with heavily limited training data. Additionally, it is much more robust to out-of-distribution samples, e.g., in-the-wild poses/images and out-of-frame cropping. ICON takes a step towards robust 3D clothed human reconstruction from in-the-wild images. This enables creating avatars directly from video with personalized and natural pose-dependent cloth deformation.
| Author(s): | Yuliang Xiu and Jinlong Yang and Dimitrios Tzionas and Michael J. Black |
| Book Title: | 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022) |
| Pages: | 13286--13296 |
| Year: | 2022 |
| Month: | June |
| Publisher: | IEEE |
| Department(s): | Perceiving Systems |
| Research Project(s): |
Implicit Representations
|
| Bibtex Type: | Conference Paper (inproceedings) |
| Paper Type: | Conference |
| DOI: | 10.1109/CVPR52688.2022.01294 |
| Event Name: | IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022) |
| Event Place: | New Orleans, Louisiana |
| Address: | Piscataway, NJ |
| ISBN: | 978-1-6654-6947-0 |
| State: | Published |
| Links: |
Home
Code Demo Video arXiv |
| Video: | |
| Attachments: |
Paper
Sup. Mat. Poster |
|
BibTex @inproceedings{xiu2022icon,
title = {{ICON}: {I}mplicit {C}lothed humans {O}btained from {N}ormals},
author = {Xiu, Yuliang and Yang, Jinlong and Tzionas, Dimitrios and Black, Michael J.},
booktitle = {2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022)},
pages = {13286--13296 },
publisher = {IEEE},
address = {Piscataway, NJ},
month = jun,
year = {2022},
doi = {10.1109/CVPR52688.2022.01294},
month_numeric = {6}
}
|
|