ACTOR: Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
2021-10-13
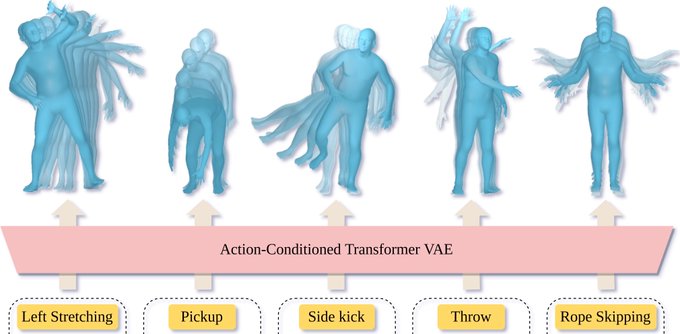
ACTOR learns an action-aware latent representation for human motions by training a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on a categorical action. ACTOR uses a transformer-based architecture to encode and decode a sequence of parametric SMPL human body models estimated from action recognition datasets.
ACTOR learns an action-aware latent representation for human motions by training a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on a categorical action. ACTOR uses a transformer-based architecture to encode and decode a sequence of parametric SMPL human body models estimated from action recognition datasets.
| Author(s): | Mathis Petrovich, Michael J. Black, Gül Varol |
| Department(s): |
Perceiving Systems |
| Publication(s): |
Action-Conditioned {3D} Human Motion Synthesis with Transformer {VAE}
|
| Authors: | Mathis Petrovich, Michael J. Black, Gül Varol |
| Release Date: | 2021-10-13 |
| Repository: | https://github.com/Mathux/ACTOR |